Base de données

- Une base de données, c'est quoi?
- Domaines
- Types
- Langages de requête
- Bases de données persistantes et en mémoire
- Système de base de données serveur ou fichier
- Bases de données distribuées
- Remarque de dernière minute
- Sources
Quand on vous dit: "base de données", que vous vient-il à l'esprit? Selon votre niveau d'expertise et votre âge, peut-être penserez-vous à un index téléphonique, des classeurs à tiroirs pour dossiers suspendus, ou encore à une bibliothèque voire le mundaneum. Si vous vous y connaissez un peu, vous verrez des fichiers texte, des tableurs ou des schémas de base de données. Pourquoi pas des serveurs à perte de vue? Et enfin, internet!
Une base de données, c'est quoi?
Il faut probablement faire une petite mise au point lexicale. On parle ici de base de données. Mais vous pourrez croiser "banque de données" et "source de données". Y a-t-il une différence entre ces termes? Sont-ils des synonymes? Sinon, que se cache-t-il derrière ces concepts?
Base de données : Ensemble de données organisé en vue de son utilisation par des programmes correspondant à des applications distinctes et de manière à faciliter l'évolution indépendante des données et des programmes.
Banque de données : Ensemble de données relatif à un domaine défini de connaissances et organisé pour être offert aux consultations d'utilisateurs.
Source de données : Une source de données est un endroit où l’information est recueillie. La source peut être une base de données, un fichier plat, un document XML ou tout autre format qu’un système peut lire. L’entrée est capturée sous la forme d’un ensemble d’enregistrements contenant des informations utilisées dans le flux de travail.
Le SPF Économie propose une définition très intéressante de ce qu'est une base de données.
Pour constituer une base de données, les éléments qui la composent doivent être indépendants, c'est-à-dire séparables les uns des autres sans que cela réduise la valeur informative de chaque élément.
Un roman n'est pas une base de données mais une encyclopédie, un répertoire de poèmes, le sont.
Ensuite, les données doivent être disposées de manière systématique ou méthodique, ce qui exclut les ensembles de données non organisées, et être accessibles individuellement. Il faut donc qu’un moyen (tel un index, un plan de classement, un outil électronique de recherche ou tout autre moyen) permette de rechercher un élément particulier.
Une base de données nécessite un outil d'accessibilité et une méthode d'organisation.
Sont couvertes les bases de données sur support électronique ou sur support non électronique tel que le papier
Le support ne doit pas forcément être numérique.
Le support papier a des avantages non négligeables. Il peut fonctionner sans électricité. Il ne peut pas être virussé. Il ne consomme normalement pas d'énergie.
Ce support amène quand même pas mal de désavantages. Il nécessite un classement rigoureux. L'information n'est pas facilement partageable. Il engendre une perte de temps d'accessibilité et de place. Les sauvegardes de sécurité sont plus ou moins onéreuses en fonction du volume.
On pourrait donc dire que plusieurs sources de données sont méthodiquement organisées en base de données d'enregistrements structurés. Les enregistrements sont individuellement consultables et modifiables via un système de gestion de base de données. L'ensemble des données d'un même domaine constitue une banque de données. Une banque de données peut devenir à son tour une source de données. Aucun des trois concepts précités ne doit obligatoirement être numérique.
Domaines
Les bases de données sont présentes dans tous les domaines de notre société moderne : cadastre, biens immobiliers à louer ou à vendre, catalogue musicale ou cinématographique, les who's who, la finance, le système bancaire, les sciences, l'administration, les ERP, … Les bases de données sont des outils indispensables, incontournables. Le passage de celles-ci au support numérique a démocratisé et facilité leur usage au quotidien, les rendant inéluctables.
Types
Plusieurs types de base de données existent et chacune a ses spécificités. Je ne vais pas tenter d'expliquer en profondeur (en tout cas pas dans cet article) le fonctionnement de ces différents types de système de gestion de base de données. Je me contenterai de dresser un "big picture" de celles-ci.
Citons les bases de données :
Hiérarchique
C'est un des premiers types de base de données créés. Ce type de base de données n'est que très rarement utilisé de nos jours. Il est souvent implémenté directement dans les SGBDR ou les DB No-SQL qui ont la capacité de gérer ce type de structure.
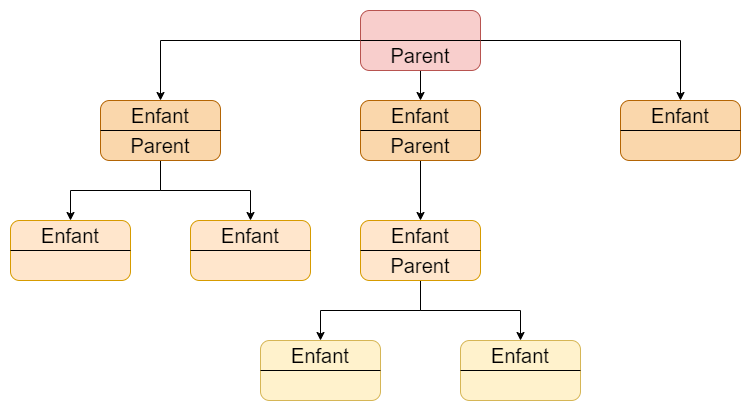
Les bases de données hiérarchiques sont représentées à l'aide d'une structure arborescente. Dans ce type de structure, un parent peut avoir de 0 à plusieurs enfants. Un enfant peut à son tour devenir un parent. Un enfant n'aura jamais que 1 et 1 seul parent.
On retrouve ce type de structure dans :
- La gestion des dossiers et des fichiers;
- La base de registre de Windows;
- La taxonomie;
- Les catégories du menu d'un site;
- Les nomenclatures logistiques (Bill Of Materials);
- Domaine banque-assurance.
Bien que ce type de données n'ait jamais été un problème à stocker dans une base de données relationnelles, il était souvent très compliqué de récupérer ces données récursives directement dans le SGBDR. Il fallait rapatrier les données et les traiter via un langage de programmation. Certains SGBDR permettaient de traiter les données via des langages SQL propres à la base de données (T-SQL, PG/SQL, PL/SQL, …). Depuis fin des années 2010, les requêtes CTE (Common Table Expression) sont implémentées dans tous les grands SGBDR. Il est désormais possible de traiter les données récursivement avec une requête telle que WITH RECURSIVE req_cte (…) AS (…) SELECT … .
Inconvénients
Ce système n'est pas flexible. La moindre modification a un impact énorme sur la structure globale de la base de données et donc, sur les applications qui en découlent.
De plus, ce type ne permet pas de décrire des structures complexes avec des relations de N à N (plusieurs à plusieurs). Par exemple, un médecin aura plusieurs patients. Mais un patient pourrait consulter plusieurs médecins. Et pour ne citer que lui, l'ornithorynque peut, à lui-seul, mettre à mal la classification des être vivants.
Ce manque de flexibilité va amener la création des bases de données réseau.
À propos des bases de données hiérarchiques
Réseau
Ce type de base de données a été créé pour pallier aux manques des bases de données hiérarchiques dans la gestion des relations N à N (plusieurs à plusieurs).
Avantages
Tous les objets peuvent être liés entre eux. La seule manière d'accéder à un enregistrement est via un des chemins d'accès qui mènent à cet enregistrement. Ces bases de données sont simples à conceptualiser et facile à concevoir. Ce système utilise un schéma qui spécifie quel type d'enregistrement peut être imbriqué dans quel autre type. L'intégrité des données y est vérifiée. Le SQL est utilisé pour effectuer les requêtes.
Inconvénients
L'implémentation est compliquée car tous les enregistrements sont des pointeurs, rendant ce type de structure plus complexe que le type hiérarchique. L'insertion, la mise à jour et la suppression des enregistrements nécessitent de nombreux ajustements de pointeurs, ce qui peut amener des problèmes de performance. Il est difficile de modifier la structure d'une base de donnés réseau une fois peuplée.
À propos des bases de données réseau
Base de données réseau — Wikipédia
Network Database, Relational DB, and Graph DB Compared - Raima
Orientées Clé-Valeur (No-SQL)
Les bases de données clé-valeur sont l'une des formes les plus simples de systèmes de gestion de bases de données, conçues pour stocker les données de manière à permettre un accès et une récupération à grande vitesse. Dans ce paradigme, les données sont organisées comme une collection de paires clé-valeur, où chaque clé agit comme un identifiant unique pour la valeur correspondante.
Avantages
Cette structure simpliste rend les bases de données clé-valeur exceptionnellement rapides et efficaces, ce qui les rend adaptées aux applications qui nécessitent une surcharge minimale et des temps d'accès rapides, telles que les mécanismes de mise en cache, le stockage de session et l'analyse en temps réel.
L'un des principaux avantages des bases de données clé-valeur est leur flexibilité dans la gestion de différents types de données. Étant donné que la valeur peut provenir de n'importe quel format de données, allant de simples chaînes et entiers à des structures plus complexes telles que des objets JSON ou des données binaires, les développeurs peuvent facilement adapter la base de données pour répondre aux exigences spécifiques de leurs applications. De plus, les magasins clé-valeur sont souvent sans schéma, ce qui peut réduire considérablement la complexité de la gestion des bases de données et permettre un développement agile et des mises à jour itératives.
Inconvénients
L'un des principaux inconvénients est l'absence de capacités d'interrogation complexes. Contrairement aux bases de données relationnelles qui prennent en charge SQL et permettent des requêtes complexes impliquant plusieurs clés et relations, les magasins clé-valeur fournissent généralement des fonctionnalités de requête très basiques, souvent limitées à de simples recherches basées uniquement sur des clés. Cela peut entraver leur adéquation aux applications nécessitant une récupération de données, des analyses ou des rapports complexes.
Un autre inconvénient est le potentiel de redondance et d'incohérence des données. Dans un modèle clé-valeur, il peut être nécessaire de dupliquer les données associées sur plusieurs clés pour maintenir les performances, ce qui entraîne des problèmes d'intégrité des données et une augmentation de la surcharge de stockage. Cette redondance peut compliquer les mises à jour, car les modifications doivent être apportées à plusieurs endroits, ce qui augmente le risque d'écarts.
De plus, les bases de données clé-valeur ne disposent généralement pas de fonctionnalités de sécurité robustes et d'une prise en charge avancée des transactions que l'on trouve dans les systèmes de base de données plus matures. Cette absence peut entraîner des problèmes de gestion des contrôles d'accès des utilisateurs et d'assurer la cohérence des données lors d'opérations simultanées.
À propos des bases de données orientées clé-valeur
- Qu'est qu'une base de données clé-valeur ?
- Bases de données clé-valeur — Wikipédia
- Base de données NoSQL : l’essentiel sur le modèle clé-valeur | LeMagIT
- Base de données clé-valeur | Comment les informations sont stockées
- Qu’est-ce qu’une base de données clé-valeur ? | Pure Storage
- Key Value Store : de quoi s’agit-il ? - IONOS
Orientées Colonne (No-SQL)
Les bases de données en colonnes sont conçues pour optimiser le stockage et l'extraction des données en organisant les informations en colonnes plutôt qu'au format traditionnel basé sur des lignes. Cette architecture est particulièrement avantageuse pour les charges de travail analytiques, où les opérations de lecture lourde et les requêtes complexes sont courantes. Dans une base de données en colonnes, chaque colonne est stockée séparément, ce qui permet une compression plus efficace des données et de meilleures performances lors de l'accès à des jeux de données volumineux, en particulier lors d'agrégations et de calculs.
Avantages
Lorsqu'une requête est exécutée, le moteur de base de données peut rapidement analyser uniquement les colonnes pertinentes nécessaires à cette opération, ce qui réduit considérablement la quantité de données lues à partir du stockage. Par exemple, si une requête demande des données à partir d'une colonne spécifique d'une table contenant des millions d'enregistrements, une base de données en colonnes ne récupère que cette colonne, en ignorant complètement les données non pertinentes. Cette conception accélère non seulement la récupération des données, mais améliore également l'utilisation des ressources de mémoire et de stockage.
De plus, les bases de données en colonnes exploitent divers algorithmes de compression adaptés à des types de données spécifiques, ce qui permet de réaliser des économies d'espace considérables, ce qui peut entraîner une réduction des coûts de stockage et une amélioration des performances d'E/S. Ils sont particulièrement bien adaptés aux applications analytiques telles que la Business Intelligence, l'analyse du Big Data et l'entreposage de données, où la capacité à effectuer des agrégations rapides sur de vastes ensembles de données est essentielle pour les processus de prise de décision. Alors que les organisations se tournent de plus en plus vers des stratégies axées sur les données, les bases de données en colonnes jouent un rôle central dans l'analyse et la récupération efficaces des données dans divers secteurs.
Inconvénients
Bien que les bases de données en colonnes offrent de nombreux avantages, tels que l'amélioration des performances des requêtes et une compression efficace des données, elles présentent également plusieurs inconvénients à prendre en compte. L'un des principaux inconvénients est la complexité de la modélisation des données. Les bases de données en colonnes nécessitent une approche différente de la conception des données par rapport aux bases de données traditionnelles orientées lignes, ce qui peut entraîner une courbe d'apprentissage plus abrupte pour les développeurs et les administrateurs de bases de données. Cela peut entraîner une augmentation du temps de développement et des pièges potentiels lors de la mise en œuvre.
Une autre préoccupation est l'arbitrage de performance pour les opérations basées sur les transactions. Les bases de données en colonnes excellent dans les requêtes analytiques qui impliquent la lecture de grands volumes de données, mais elles peuvent avoir du mal avec des charges de travail lourdes en écriture. Dans les scénarios où des mises à jour, des insertions ou des suppressions fréquentes sont nécessaires, les performances peuvent se dégrader car la base de données doit gérer les données de manière plus fragmentée, ce qui peut entraîner une latence accrue.
Enfin, le choix de bases de données en colonnes peut limiter la compatibilité avec les applications et les outils existants conçus autour de structures de données orientées lignes. Cela peut nécessiter des modifications de l'architecture de l'application, ce qui peut entraîner des investissements supplémentaires en temps et en ressources. Enfin, si les bases de données en colonnes peuvent permettre des économies d'espace significatives grâce à la compression, la surcharge liée à la gestion de ces formats de données compressés peut compliquer l'administration et entraîner une augmentation de l'utilisation du processeur, ce qui a un impact supplémentaire sur les performances dans des contextes spécifiques.
À propos des bases de données orientées colonne
- Base de données orientée colonnes | Comment fonctionne ce modèle ? - IONOS
- What is a Column Store Database?
- What is a columnar database? Here are 35 examples.
- Column-Oriented Databases, Explained - KDnuggets
Orientées document (No-SQL)
Les bases de données de documents, ou magasins de documents, sont un type de base de données NoSQL conçu pour stocker, récupérer et gérer des données semi-structurées sous forme de documents, généralement à l'aide de formats tels que JSON, BSON ou XML.
Avantages
Contrairement aux bases de données relationnelles traditionnelles qui s'appuient sur des schémas et des tables fixes, les bases de données de documents offrent une approche plus flexible, permettant aux développeurs de stocker facilement des structures de données complexes sans avoir à définir un schéma strict au départ. Cette flexibilité est particulièrement bénéfique dans les environnements de développement en évolution rapide d'aujourd'hui, où les exigences peuvent changer rapidement et où les conceptions d'applications doivent évoluer pour s'adapter aux nouvelles fonctionnalités.
L'un des principaux avantages des bases de données documentaires est leur capacité à traiter efficacement les données non structurées ou semi-structurées. Par exemple, dans des applications telles que les systèmes de gestion de contenu, les plateformes de commerce électronique ou l'analyse en temps réel, les données peuvent ne pas s'intégrer parfaitement dans les tableaux. Les magasins de documents peuvent encapsuler différents types de données et relations dans un seul document, ce qui facilite la gestion et l'interrogation d'ensembles de données complexes. Cette structure permet également des opérations de lecture et d'écriture plus rapides, car les données associées peuvent souvent être stockées ensemble, ce qui réduit le besoin d'opérations de jointure coûteuses que l'on trouve couramment dans les bases de données relationnelles.
En outre, les bases de données de documents offrent généralement une évolutivité horizontale, ce qui les rend adaptées aux applications qui connaissent de gros volumes de données ou des charges de trafic élevées. En distribuant les documents sur un cluster de serveurs, ils peuvent gérer efficacement des charges de travail accrues sans sacrifier les performances. Les bases de données de documents ont gagné en popularité dans la communauté des développeurs en raison de leur évolutivité, de leur flexibilité et de leur facilité d'utilisation.
Inconvénients
L'un des principaux inconvénients est le potentiel de redondance des données, car des documents similaires peuvent être stockés avec des informations en double. Cela augmente non seulement les besoins en stockage, mais peut également compliquer l'intégrité et la cohérence des données, ce qui rend difficile la gestion des mises à jour des documents. De plus, l'absence d'un schéma fixe, tout en offrant de la flexibilité, peut entraîner des problèmes de qualité et d'uniformité des données. En l'absence d'une structure définie, les développeurs doivent gérer et appliquer soigneusement des règles de validation des données, ce qui peut augmenter la complexité du développement d'applications.
Une autre préoccupation importante est la complexité des requêtes dans les bases de données de documents. Bien qu'elles prennent en charge de puissantes fonctionnalités de requête, les jointures complexes sont généralement plus difficiles à mettre en œuvre que les bases de données relationnelles. Par conséquent, les utilisateurs peuvent être confrontés à des défis lorsqu'ils doivent effectuer des requêtes complexes qui s'étendent sur plusieurs documents ou collections, ce qui peut entraîner des goulets d'étranglement des performances. De plus, l'absence de conformité ACID dans certaines bases de données de documents peut présenter des risques pour les applications nécessitant une prise en charge transactionnelle stricte. Cela peut entraîner des situations où l'intégrité des données est compromise, en particulier dans les scénarios impliquant des écritures simultanées.
Les considérations de coût sont également pertinentes pour les bases de données documentaires, notamment en termes d'infrastructure et de maintenance nécessaires. À mesure que les volumes de données augmentent, les entreprises peuvent se trouver à devoir investir dans du matériel plus performant ou des architectures plus complexes pour garantir des performances adéquates, ce qui peut entraîner une augmentation des dépenses opérationnelles. Enfin, il peut être difficile de trouver des professionnels qualifiés capables de travailler avec des bases de données de documents, car elles nécessitent souvent des compétences et des connaissances différentes de celles des systèmes de bases de données relationnelles traditionnels.
À propos des bases de données orientées document
- Bases de données orientées documents | Explications et avantages - IONOS
- Base de données orientée documents — Wikipédia
- Document Database - NoSQL | MongoDB
- Qu’est-ce qu’une base de données documentaire ? - Explication des bases de données documentaires et des magasins - AWS
- An Introduction to Document-Oriented Databases | DigitalOcean
Orientées graphe (No-SQL)
Les bases de données orientées graphes sont conçues pour stocker, récupérer et interroger efficacement des données qui sont intrinsèquement connectées et peuvent être représentées sous forme de graphique. Contrairement aux bases de données relationnelles traditionnelles, qui utilisent des tables et des lignes pour représenter les données et les relations, les bases de données orientées graphes utilisent des nœuds, des arêtes et des propriétés pour décrire et analyser les relations de manière plus intuitive.
Avantages
Cette structure permet la représentation naturelle de relations complexes, ce qui rend les bases de données orientées graphes particulièrement adaptées à des applications telles que les réseaux sociaux, les systèmes de recommandation, la détection des fraudes et l'analyse des réseaux.
Un autre avantage non négligeable des bases de données orientées graphes est leur évolutivité. À mesure que le volume et la complexité des données augmentent, les bases de données orientées graphe peuvent facilement s'adapter à ces modifications sans affecter considérablement les performances. Leur conception permet une traversée efficace de grands ensembles de données, permettant un accès rapide aux informations associées. Cela est particulièrement avantageux dans les environnements dynamiques où de nouvelles relations émergent fréquemment, ce qui permet aux organisations de s'adapter rapidement et de tirer des informations de leurs données.
En outre, les bases de données orientées graphe excellent dans le traitement des données semi-structurées et non structurées. De nombreuses applications du monde réel impliquent des données qui ne s'intègrent pas parfaitement dans des schémas prédéfinis, ce qui fait des bases de données de graphes une solution idéale. Ils offrent une flexibilité dans la modélisation des données, ce qui permet aux développeurs de faire évoluer leurs bases de données en fonction de l'évolution des besoins au fil du temps, sans avoir besoin de migrations ou de reconceptions importantes.
Enfin, les bases de données orientées graphe sont souvent dotées de langages de requête puissants conçus pour les requêtes de relations complexes. Le langage Cypher facilite l'écriture de requêtes expressives pour récupérer des données basées sur des relations complexes, et ce, sans trop de difficulté. Cela améliore non seulement la productivité des développeurs, mais permet également aux analystes commerciaux d'extraire des informations à partir des données sans avoir besoin d'une expertise technique approfondie.
Inconvénients
L'une des principales préoccupations est l'évolutivité ; À mesure que le volume de données et le nombre de relations augmentent, les performances peuvent se dégrader. Cela est particulièrement évident dans les scénarios où de grands ensembles de données sont impliqués, où les performances des requêtes peuvent ne pas être aussi optimisées en raison de la nature complexe de la traversée de graphe.
La courbe d'apprentissage des développeurs et des architectes de données qui sont habitués aux bases de données relationnelles ou NoSQL traditionnelles, peut être abrupte.
L'écosystème entourant les bases de données orientées graphes, peu mature, peut manquer d'outils et de bibliothèques robustes pour la gestion, la sauvegarde, la surveillance et l'analyse des données, ce qui rend plus difficile la mise en œuvre de solutions complètes.
L'interopérabilité peut également être un défi, en particulier dans les environnements où plusieurs systèmes de base de données sont utilisés. L'intégration de bases de données de graphes à l'infrastructure existante, en particulier si elle est principalement relationnelle, peut nécessiter des efforts considérables et entraîner des complications en matière de cohérence des données et de protocoles d'accès.
À propos des bases de données orientées graphe
- Network Database, Relational DB, and Graph DB Compared - Raima
- Base de données vectorielle et base de données orientée graphe : quelles sont les différences ? | Elastic Blog
- Qu’est-ce qu’une base de données orientée graphe | Oracle France
- Base de données orientée graphe — Wikipédia
- Graph database | La base de données basée sur les graphes - IONOS
Relationnelles (RDBMS)
Les systèmes de gestion de bases de données relationnelles (SGBDR) sont des outils essentiels pour stocker, gérer et récupérer des données structurées. Ils s'appuient sur un format tabulaire (à l'aide de lignes et de colonnes) pour représenter les données, ce qui facilite la compréhension et la manipulation des informations.
Les applications modernes et conviviales de modélisation de base de données et les langages de requête tels que SQL (Structured Query Language) offrent un moyen simple d'apprendre l'organisation et la récupération des données en modèle relationnel. Les utilisateurs avancés pourront, quant à eux, tirer parti des fonctionnalités du SGBDR telles que l'indexation, les transactions et l'intégrité référentielle pour optimiser les performances et garantir l'exactitude des données au sein d'applications complexes.
Avantages
L'un des avantages significatifs du SGBDR est l'intégrité et la précision des données, obtenues grâce à la normalisation et à l'application de contraintes, ce qui permet de maintenir des relations claires entre les tables. Les utilisateurs avancés bénéficient de la possibilité d'implémenter des requêtes complexes et des opérations de jointure, ce qui permet une analyse plus approfondie des données interconnectées. Les SGBDR fournissent des solutions robustes pour la gestion des transactions (ACID), garantissant que les données restent cohérentes même en cas de défaillance du système.
Inconvénients
Malgré leurs nombreux avantages, les systèmes SGBDR peuvent présenter des inconvénients. Pour les utilisateurs novices, la courbe d'apprentissage associée aux principes de conception SQL et de base de données peut être difficile, ce qui peut entraîner des difficultés potentielles dans l'utilisation efficace de ces systèmes. Les utilisateurs avancés peuvent trouver que les SGBDR ne conviennent pas à la gestion de données non structurées ou semi-structurées, telles que les fichiers multimédias ou les gros blobs de texte, où les bases de données NoSQL peuvent offrir plus de flexibilité. Des problèmes de performances peuvent également survenir avec les SGBDR à mesure que le volume de données augmente, en particulier si les requêtes sont mal conçues ou si les stratégies d'indexation ne sont pas optimisées. De plus, le schéma rigide des SGBDR peut limiter la capacité à s'adapter aux exigences changeantes en matière de données sans restructuration importante.
Fonctionnalités
Les SGBDR offrent une gamme de fonctionnalités adaptées pour répondre aux différents besoins en matière de gestion des données. Les opérations fondamentales telles que CRUD (Create, Read, Update, Delete) peuvent être effectuées avec des commandes SQL traditionnelles. Le contrôle des transactions garantit des opérations atomiques, cohérentes, isolées et durables (ACID). Les capacités d'indexation permettent d'accélérer la récupération des données. Les procédures stockées et les déclencheurs sont des outils puissants pour les utilisateurs avancés car ils permettent l'automatisation et la personnalisation des tâches. Les rôles et les autorisations des utilisateurs assurent la sécurité des données. Ils sont essentiels pour protéger les informations sensibles et gérer efficacement les accès. Dans l'ensemble, le SGBDR constitue une solution polyvalente et robuste pour la gestion des données.
À propos des bases de données relationnelles
Qu’est-ce qu’une base de données relationnelle ? | Oracle France
Base de données relationnelle : l’essentiel à connaître - IONOS
Vectorielles (VBDBMS)
Comment ça fonctionne?
Ces systèmes vont stocker, gérer et indexer efficacement des grandes quantités de vecteurs. Un vecteur est une représentation d'un mot, d'une phrase, d'une image, d'une vidéo, d'un son, d'une onde, sous forme de matrice de nombres. Ces matrices sont générées par des modèles de Machine Learning. Lors d'une recherche, le système va convertir la requête en vecteur. Le système ne va pas chercher une correspondance exact avec d'autres items mais une similarité.
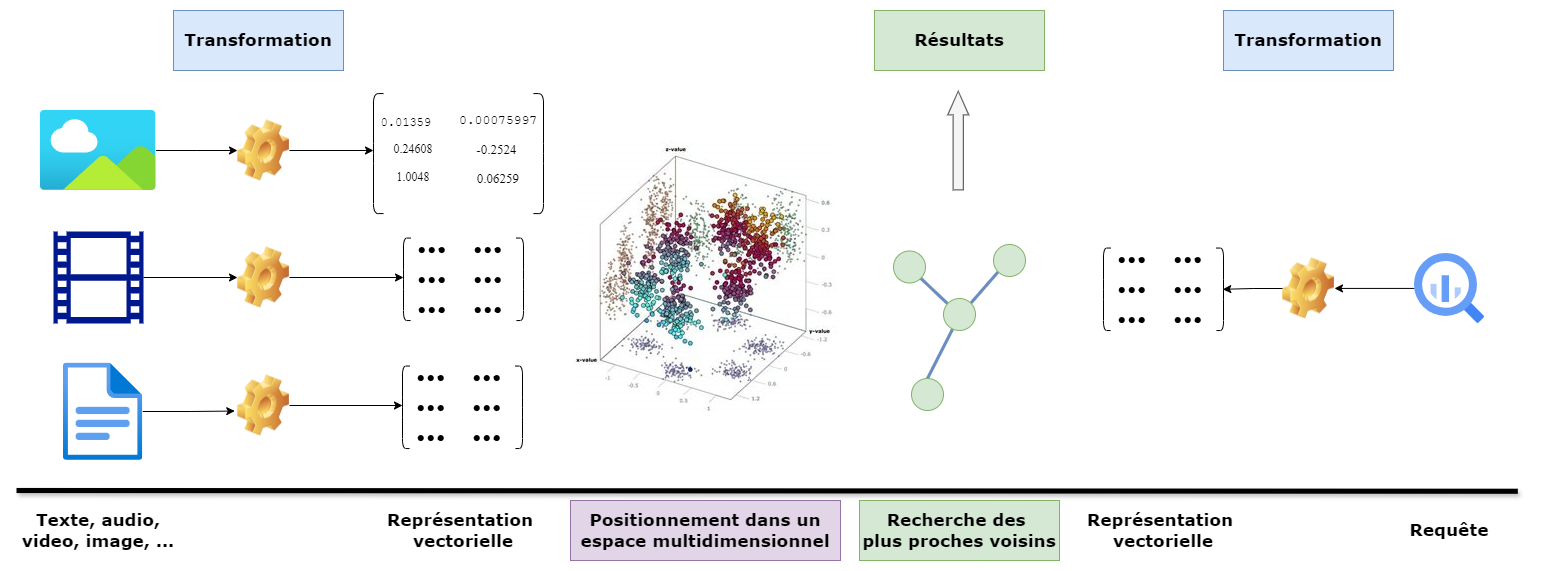
À quoi servent les bases de données vectorielles?
Ces systèmes sont intiment liés au Machine Learning, au traitement du langage naturel et à l'IA de manière générale. Les bases de données vectorielles sont utilisées dans :
- Les systèmes de recommandation (Netflix, Spotify, Amazon, …);
- La recherche d'images (Google);
- Le traitement du langage naturel (moteur de recherche);
- La bio-informatique, on y représente les séquences génétiques ou les structures protéiques sous forme de vecteurs;
- La détection des anomalies comme par exemple dans la recherche de séismes en Antarctique.
À propos des bases de données vectorielles
- Que sont les plongements vectoriels ? | Guide complet sur les plongements vectoriels | Elastic
- Qu'est-ce qu'une base de données vectorielle ? | Guide complet sur la base de données vectorielle | Elastic
- Qu’est-ce qu’une base de données vectorielle ? | IBM
- Qu’est-ce qu’une base de données vectorielle ? | Cloudflare
- Bases de données vectorielles : la nouvelle révolution du Big Data
Orientées objet
Les bases de données orientées objet (OODB) représentent un changement de paradigme par rapport aux bases de données relationnelles traditionnelles, adoptant les principes de la programmation orientée objet (POO). Dans une OODB, les données sont stockées sous forme d'objets, un peu comme dans la POO, ce qui permet une manière plus intuitive de modéliser des relations et des entités complexes.
Avantages
Cette approche permet aux développeurs de travailler directement avec des structures de données comme ils le feraient en programmation, ce qui peut simplifier le développement d'applications. Les objets peuvent encapsuler à la fois des données et un comportement, ce qui permet d'obtenir un modèle plus cohérent qui reflète plus précisément les scénarios du monde réel que les modèles relationnels, où les données sont souvent fragmentées entre les tables.
L'un des principaux avantages des bases de données orientées objet est leur capacité à gérer des types de données et des relations complexes, y compris des données multimédias, des collections et des hiérarchies, qui sont de plus en plus courantes dans les applications modernes. Étant donné que les OODB prennent en charge des fonctionnalités telles que l'héritage et le polymorphisme, ils peuvent offrir plus de flexibilité en termes de représentation et d'accès aux données. Par exemple, si un nouveau type d'objet doit être créé, il peut hériter des propriétés et des méthodes d'objets existants, ce qui permet de réutiliser le code et de faciliter la maintenance.
Inconvénients
Bien que les bases de données orientées objet (OODB) offrent plusieurs avantages, tels qu'une intégration transparente avec les langages de programmation orientés objet et une meilleure gestion des types de données complexes, elles présentent également des inconvénients notables. L'un des inconvénients importants est le manque d'adoption et de normalisation généralisées, ce qui peut entraîner des problèmes de compatibilité et un nombre limité de développeurs qualifiés familiarisés avec les concepts et les implémentations OODB. Cette pénurie peut entraîner une augmentation des coûts de développement et de maintenance, car les organisations peuvent avoir du mal à trouver du personnel et des ressources expérimentés pour gérer efficacement leurs bases de données orientées objet.
Les OODB peuvent présenter des défis en termes de performances et d'évolutivité. Les bases de données relationnelles traditionnelles sont souvent optimisées pour la vitesse et l'efficacité des requêtes avec des données structurées, tandis que les OODB peuvent rencontrer des goulots d'étranglement lors de l'exécution de requêtes complexes ou de la gestion de gros volumes de données. La flexibilité inhérente aux OODB peut également compliquer la conception de stratégies d'indexation et de récupération efficaces. Par conséquent, les organisations doivent évaluer soigneusement leurs cas d'utilisation spécifiques et leurs exigences en matière de données avant de s'engager dans ce paradigme de base de données.
Un autre inconvénient est la complexité du modèle de données introduit par les OODB. Contrairement aux bases de données relationnelles, qui utilisent des tables et des schémas standardisés, les OODB s'appuient sur des objets, des classes et des hiérarchies d'héritage, ce qui les rend plus difficiles à comprendre et à gérer pour ceux qui sont habitués aux systèmes de bases de données traditionnels. Cette complexité peut entraîner des difficultés lors de la migration des données et de l'intégration avec d'autres systèmes, car l'harmonisation des structures d'objets avec les bases de données relationnelles existantes peut nécessiter des efforts et des ressources considérables.
À propos des bases de données orientées objet
- Base de données orientées objet : explications + avantages et inconvénients - IONOS
- Base de données orientée objet — Wikipédia
- Les bases de données Orientées Objet - uliege.be
- What Is An Object-Oriented Database? | MongoDB
- Object-Oriented Database {Concepts, Examples, Pros and Cons}
- Definition and Overview of ODBMS - GeeksforGeeks
Langages de requête
Les langages de requête de base de données sont des outils essentiels qui facilitent l'interaction avec les bases de données, permettant aux utilisateurs de récupérer, manipuler et gérer efficacement les données. Le plus largement reconnu d'entre eux est SQL (Structured Query Language), qui constitue l'épine dorsale des systèmes de gestion de bases de données relationnelles tels que MySQL, PostgreSQL et Oracle. SQL fournit un moyen standardisé d'effectuer diverses opérations telles que la sélection, l'insertion, la mise à jour et la suppression de données, ce qui en fait un choix polyvalent pour les développeurs et les analystes de données. Sa syntaxe déclarative permet aux utilisateurs de spécifier les données qu'ils souhaitent, sans détailler les procédures sous-jacentes, simplifiant ainsi les interactions complexes avec les bases de données.
En revanche, les bases de données NoSQL introduisent une gamme de langages de requête adaptés à leurs structures uniques, tels que les bases de données basées sur des documents, des bases de données clé-valeur ou des bases de données graphiques. Par exemple, MongoDB utilise un langage de requête basé sur une syntaxe de type JSON, qui permet l'interrogation flexible de données non structurées, ce qui est idéal pour les applications nécessitant une évolutivité et des performances élevées. Dans le monde des bases de données de graphes, des langages tels que Cypher pour Neo4j et Gremlin pour Apache TinkerPop sont conçus pour exprimer efficacement les traversées de graphes et les requêtes, permettant de découvrir des relations et des connexions complexes entre les points de données.
Au-delà de SQL et NoSQL, des langages de requête spécialisés comme SPARQL ont émergé pour l'interrogation des données RDF (Resource Description Framework), principalement utilisés dans les applications du web sémantique. SPARQL permet aux utilisateurs de formuler des requêtes complexes sur divers ensembles de données, en tirant parti de la puissance des données et des ontologies liées. De plus, divers langages de programmation disposent de bibliothèques ou d'extensions, telles que LINQ en C# ou Entity Framework, qui permettent aux développeurs de créer des requêtes de base de données de manière plus intégrée au sein de leurs applications.
Alors que la technologie continue d'évoluer, le paysage des langages de requête de bases de données reste dynamique, avec de nouveaux outils et paradigmes émergeant pour répondre aux besoins en constante évolution de la gestion des données. Comprendre les forces et les faiblesses de chaque langage de requête est crucial pour les développeurs et les professionnels des données afin de sélectionner l'option la plus adaptée à leurs cas d'utilisation spécifiques, garantissant ainsi des performances et une efficacité optimales dans le traitement des données.
À propos des langages de base de données
- Types of Database Languages and Their Uses (Plus Examples) | Indeed.com
- GraphQL - Wikipedia
- Cypher (query language) - Wikipedia
- Gremlin (query language) - Wikipedia
- JSONiq - Wikipedia
- Object Query Language - Wikipedia
- RDF query language - Wikipedia
- SPARQL - Wikipedia
- SQL - Wikipedia
- XQuery - Wikipedia
- XPath - Wikipedia
Bases de données persistantes et en mémoire
Les bases de données en mémoire et les bases de données persistantes ont des objectifs distincts mais complémentaires dans le paysage du stockage et de la gestion des données. Les bases de données en mémoire privilégient la vitesse et les performances en stockant les données directement dans la RAM du système, ce qui permet des opérations de lecture et d'écriture extrêmement rapides. Cette architecture est particulièrement avantageuse pour les applications nécessitant des analyses en temps réel, telles que les systèmes de trading financier ou les plateformes de jeux. Cependant, la limitation des bases de données en mémoire réside dans leur volatilité ; Sans mécanismes de sauvegarde appropriés, les données peuvent être perdues en cas de panne de courant ou de plantage. Pour contrer cela, les bases de données persistantes conservent les données sur des supports de stockage à long terme, tels que les disques durs ou les SSD, garantissant ainsi durabilité et fiabilité. Ils sacrifient une certaine vitesse à la capacité de conserver les données au fil du temps, ce qui les rend idéaux pour les applications qui nécessitent l'intégrité des données et le stockage à long terme.
Système de base de données serveur ou fichier
Serveur
Une base de données basée sur un serveur, telle que MySQL ou PostgreSQL, fonctionne sur un système de gestion de base de données (SGBD) qui permet à plusieurs utilisateurs d'accéder aux données et de les manipuler simultanément sur un réseau. Cette approche centralisée garantit que l'intégrité des données, la sécurité et les processus de sauvegarde sont gérés efficacement, ce qui la rend idéale pour les applications à l'échelle de l'entreprise où plusieurs clients ont besoin d'un accès en temps réel à des informations à jour. De plus, les bases de données basées sur serveur offrent des fonctionnalités avancées telles que la prise en charge des transactions, des capacités d'interrogation complexes et l'évolutivité qui les rendent adaptées aux grands ensembles de données et aux applications à fort trafic.
Fichier
Une base de données basée sur des fichiers, telle qu'un simple fichier CSV ou SQLite, stocke les données dans un ou plusieurs fichiers sur un système de fichiers. Ce type de base de données est généralement plus facile à configurer et à gérer, ce qui en fait une option attrayante pour les petits projets ou les applications où la simultanéité des utilisateurs est limitée. Cependant, les bases de données basées sur des fichiers peuvent ne pas disposer des fonctionnalités robustes offertes par une solution basée sur serveur. Par exemple, ils ne prennent souvent pas en charge plusieurs utilisateurs simultanés qui modifient des données sans risquer d'être corrompus, et les requêtes peuvent être considérablement plus lentes car elles accèdent souvent à des fichiers entiers plutôt qu'à des structures de données optimisées. De plus, les bases de données basées sur des fichiers n'offrent généralement pas le même niveau de sécurité ou d'outils de gestion, ce qui les rend moins adaptées aux applications nécessitant des protocoles de traitement des données stricts.
Conclusions
Si l'accent est mis sur l'évolutivité, l'accès multi-utilisateurs et les fonctionnalités avancées, une base de données basée sur un serveur est probablement la meilleure option.
Pour les applications plus simples avec un volume de données plus faible et une simultanéité des utilisateurs plus faible, une base de données basée sur des fichiers peut offrir une solution rapide et efficace, bien qu'avec ses limites.
Bases de données distribuées
Les bases de données distribuées offrent évolutivité et résilience dans un environnement en réseau. Ces bases de données sont conçues pour répartir les données sur plusieurs serveurs ou emplacements, ce qui améliore non seulement les performances grâce à la répartition de la charge, mais offre également une tolérance aux pannes. Dans une base de données de serveur distribuée, les données sont gérées sur plusieurs serveurs qui communiquent entre eux pour assurer la cohérence et la disponibilité, ce qui rend cette architecture adaptée aux applications avec des quantités massives de données ou un trafic d'utilisateurs élevé.
Homogènes
Tous les sites ont la même configuration, tant au niveau du système d'exploitation, que du SGBD et des structures de données.
Hétérogènes
Les sites n'utilisent pas forcément les mêmes schémas, ni les mêmes SGBD: cela peut entraîner des problèmes dans le traitement des requêtes et des transactions. Ce genre d'architecture complique fortement la maintenance.
Répliquées
Redondance complète de l'ensemble de la base de données, tant pour la structure que pour les données sur chaque site.
Fragmentées
Les données sont copiées partiellement sur les différents sites sans redondance. Les fragments doivent être répartis de façon à pouvoir reconstruire les données originales sans perte. Il est possible d'effectuer des fragmentations horizontales (par lignes) et verticales (par colonnes).
Remarque de dernière minute
Bien que dans une majorité de cas, un seul système de gestion de base de données suffira amplement, il est de plus en plus fréquent dans bon nombre de modèles architecturaux modernes, de trouver plusieurs SGBD qui coexistent, chacun ayant leur domaine de prédilection.
Le pattern CQRS propose de séparer les fonctions d'écriture et lecture, tant dans l'application que dans les moyens de conserver les données et les restituer. Pour faire court, on pourrait utiliser dans ce modèle un SGBDR persistant pour toutes les opérations d'écriture de données, alors qu'on utiliserait une base de données No-SQL en mémoire vive pour ce qui concerne la restitution de données.
Dans un contexte tout autre, une application pourrait avoir à traiter d'énormes quantités de données géographiques, des données classiques et fournir des propositions d'items connexes. Un seul système pourrait peut-être fournir ses 3 services avec un bon niveau de réussite, mais en présence de données gigantesques, il serait sans doute préférable de diviser pour mieux régner. Et ainsi d'utiliser un SGBD spécialisé dans chaque tâche.
Sources
- What Are Databases? Definition, Usage, Examples and Types
- What Is a Database? | Oracle
- Source de données : Qu'est-ce que c'est avec des exemples | QuestionPro
- Base de données : qu'est-ce que c'est, et comment ça fonctionne ?
- Base de données – Concept, types et exemples
- Différents types de bases de données et leurs évolutions historiques
- NoSQL et bases de données
- Base de données : structure, utilisations...
- Les bases de données : une histoire - IONOS
- Explication des types de bases de données | LearnSQL.fr


Commentaires