Code: Table des matières
Ceci est le genre d'exercice que vous pourriez passer dans l'un ou l'autre test technique. Chez Google par exemple, il est à réaliser en 30 minutes. Il est évalué comme difficile.

Table of Contents
Description de l'exercice
`tableOfContents` qui va générer une chaîne de caractères HTML représentant une table des matières basée sur les balises d'en-tête (<h1>, <h2>, ..., <h6>) du document. Suivant les bonnes pratiques, les niveaux d'en-tête ne peuvent pas être sautés, par ex. <h1> sera suivi par <h2>.const doc = new DOMParser().parseFromString(`
<!DOCTYPE html>
<html>
<head>
<head>
<body>
<h1>Heading 1</h1>
<h2>Heading 2a</h1>
<h2>Heading 2b</h1>
<h3>Heading 3a</h1>
<h3>Heading 3b</h1>
<h4>Heading 4</h1>
<h2>Heading 2c</h1>
</body>
</html>
`)
const htmlString = tableOfContents(doc);
console.log(htmlString);
<ul>
<li>Heading 1
<ul>
<li>Heading 2a</li>
<li>Heading 2b
<ul>
<li>Heading 3a</li>
<li>Heading 3b
<ul>
<li>Heading 4a
</ul>
</li>
</ul>
</li>
<li>Heading 2c</li>
</ul>
</li>
</ul>Analyse
En soi, l'exercice n'est pas très compliqué. Le paramètre de la fonction est de type document. Il faut récupérer les balises d'en-tête (<h1>⇒<h6>). Les balises <h2> doivent être imbriquées dans la balise <h1> qui les précède. Idem pour les <h3> envers les <h2>. Et ainsi de suite jusque <h6>.
Le seul piège réside dans le saut éventuel d'une balise d'en-tête <h[x]> à une balise supérieure (<h[x+2]>) sans passer par une balise <h[x+1]>. Que faut-il faire dans ce cas-là? On insère simplement la/les balise(s) manquante(s) pour que l'arborescence soit correcte.
On retourne dans un premier temps une arborescence sous forme d'un tableau multidimensionnel (nested arrays). Dans un second temps, on se servira de cette structure pour rendre les données dans des listes imbriquées (<ul><li>). L'ultime étape consistera à pouvoir paramétrer les balises qui contiendront les données.
Code
Code d'amorce standard
L'ossature de base se compose de 3 fichiers.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Table Of Content</title>
</head>
<body>
<script src="main.js" type="module"></script>
</body>
</html>import tableOfContent from './TableOfContent.js'
const html = `
<!DOCTYPE html>
<html>
<head>
<head>
<body>
<h1>Heading 1</h1>
<h2>Heading 2a</h2>
<h2>Heading 2b</h2>
<h3>Heading 3a</h3>
<h3>Heading 3b</h3>
<h4>Heading 4</h4>
<h2>Heading 2c</h2>
</body>
</html>
`
const doc = new DOMParser().parseFromString(html,"text/html")
console.log( tableOfContent(doc) )function TableOfContent(doc) {
return "Hello world"
}
export default TableOfContentEn exécutant la page index.html et en ouvrant la console du navigateur, on devrait avoir le message Hello world affiché.
J'essaierai par la suite de convertir le contenu de main.js pour y exécuter la série de tests à l'aide d'un framework prévu à cet effet.
Obtenir les balises d'en-tête
Il semblerait que certains se demandent comment récupérer les balises spécifiques du document. Je ne me suis pas posé longtemps la question. Bon, j'avoue, j'utilise fréquemment cette méthode donc je n'ai aucun mérite à y avoir pensé.
document.querySelectorAll()
On doit spécifier les balises qu'on souhaite récupérer dans le document. Cette méthode nous renvoie un objet de type NodeList comprenant toutes les balises du document correspondant aux types de balises demandés. Il suffit alors d'itérer cet objet et effectuer le traitement nécessaire sur chaque item.
Modifions le fichier TableOfContent.js comme suit :
function TableOfContent(doc) {
return doc.querySelectorAll('h1, h2, h3, h4, h5, h6')
}
export default TableOfContentLe résultat obtenu devrait être le suivant : NodeList(7) [ h1, h2, h2, h3, h3, h4, h2 ]
Itérer les balises
L'objet NodeList a la méthode forEach() classique de l'itération. Servons-nous en comme ci-dessous :
function TableOfContent(doc) {
let result = []
doc.querySelectorAll('h1, h2, h3, h4, h5, h6').forEach(function(item, index, all) {
result.push({
tagName: item.tagName,
innerText: item.innerText
})
})
return result
}
export default TableOfContentLe résultat dans la console devrait être comme ci-après :
Array(7) [ {…}, {…}, {…}, {…}, {…}, {…}, {…} ]
0: Object { tagName: "H1", innerText: "Heading 1" }
1: Object { tagName: "H2", innerText: "Heading 2a" }
2: Object { tagName: "H2", innerText: "Heading 2b" }
3: Object { tagName: "H3", innerText: "Heading 3a" }
4: Object { tagName: "H3", innerText: "Heading 3b" }
5: Object { tagName: "H4", innerText: "Heading 4" }
6: Object { tagName: "H2", innerText: "Heading 2c" }
length: 7
<prototype>: Array []
Pour le fun
Il était possible d'écrire d'une autre façon la fonction qui transforme chaque item en objet simple et l'ajoute dans le tableau. J'avais choisi cette manière préalablement. Puis je me suis ravisé. Utiliser ce code ne facilite pas sa maintenance, ni sa compréhension. Et il n'améliore pas la rapidité ou l'adaptabilité de la fonction. Mais ça a de la gueule quand même! 😀
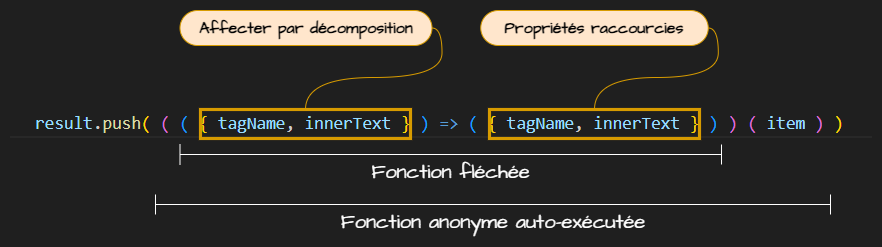
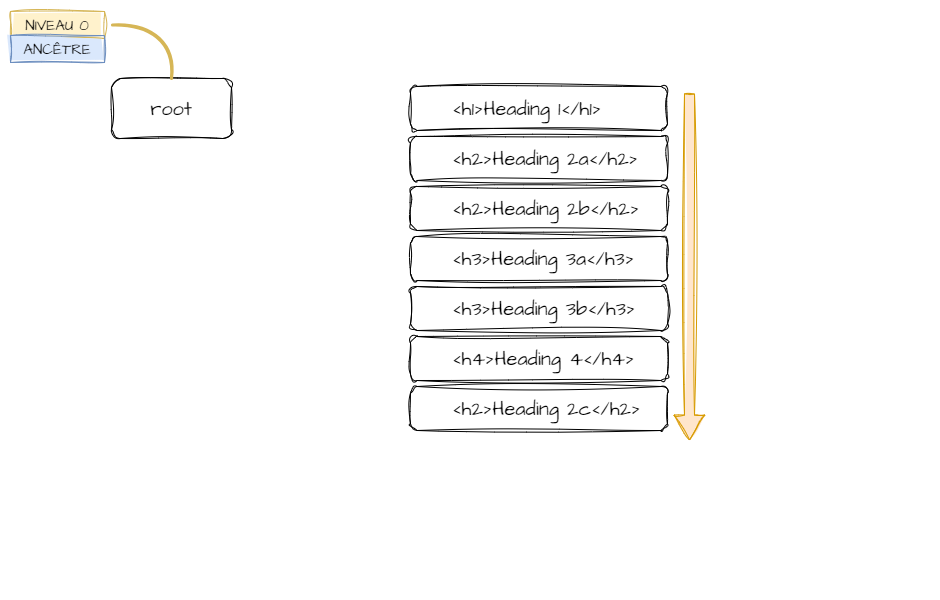
Imbriquer les nœuds
Il faut à présent transformer la structure linéaire en arborescence. Je ne vais pas me soucier dans un premier temps des éventuelles erreurs dans la structure du document. Si on passe de h1 à h3, ben, pas grave. Je me contente dans cette étape de gérer simplement les changements de niveaux.
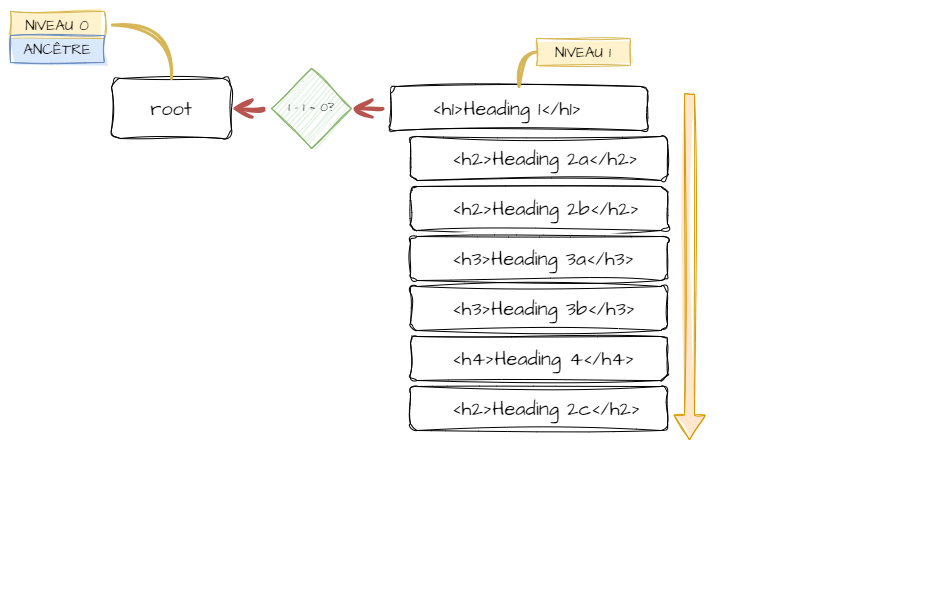
Je me suis rapidement rendu compte que régler cette transformation nécessiterait l'utilisation d'objets. Le but est de pouvoir utiliser le niveau de l'en-tête actuellement pointée afin de savoir où placer le nœud suivant. Et grâce aux objets, il sera facile de remonter l'arborescence pour trouver l'ancêtre correspondant au niveau recherché.
Il ne faut pas exclure la possibilité qu'un en-tête manque dans la séquence.
Il est également possible que l'affichage des nœuds du DOM soit modifié par le CSS.
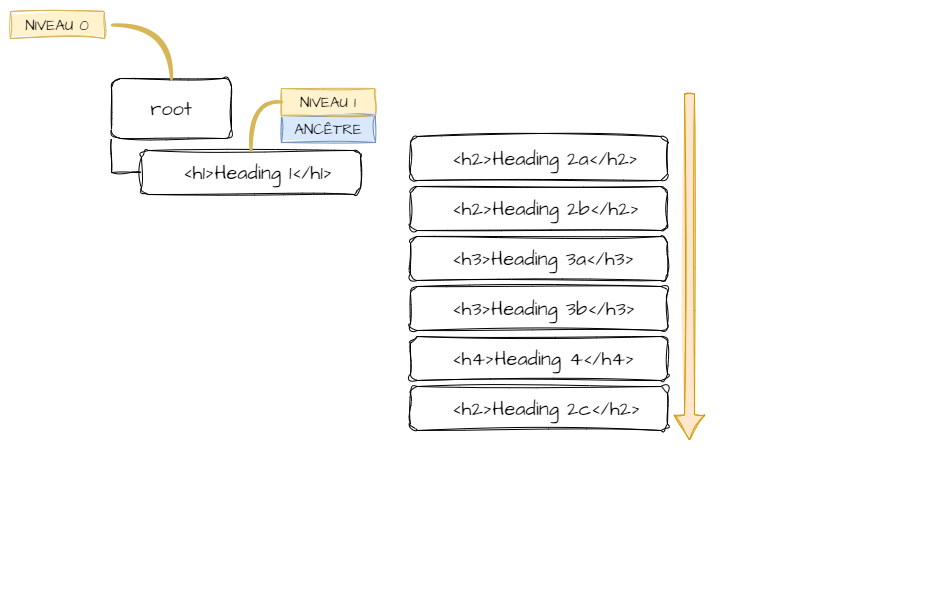
Le nœud nouvellement ajouté devient le nouveau nœud ancêtre.
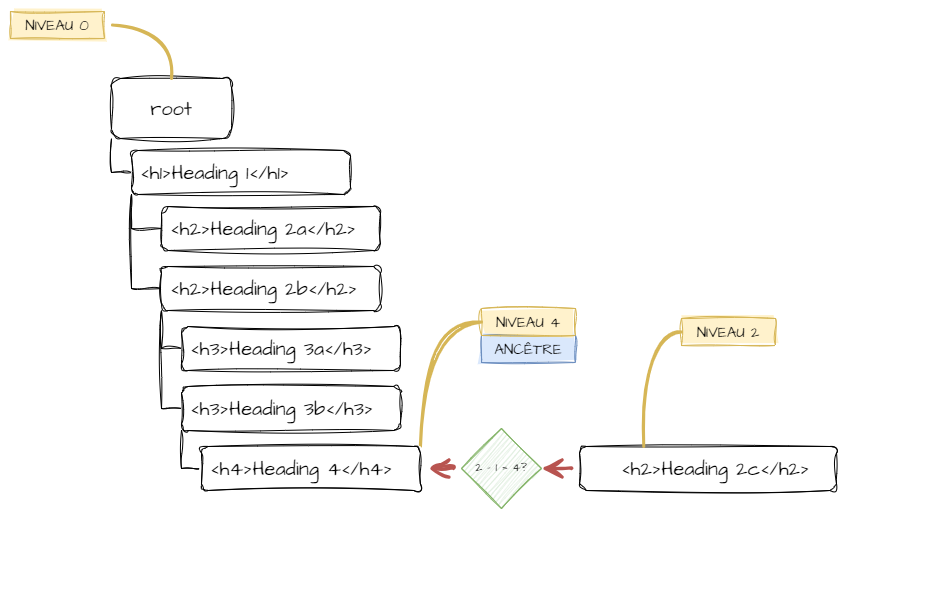
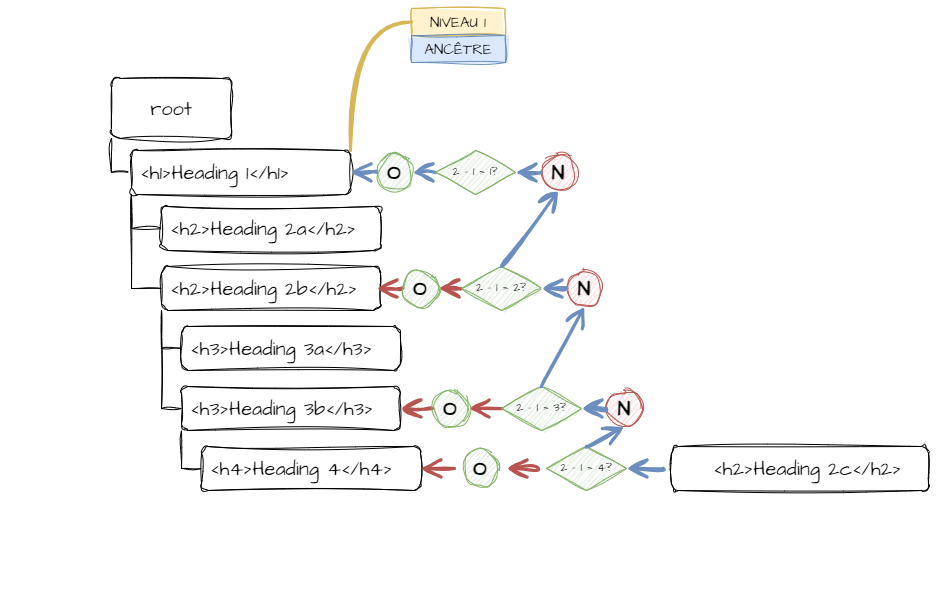
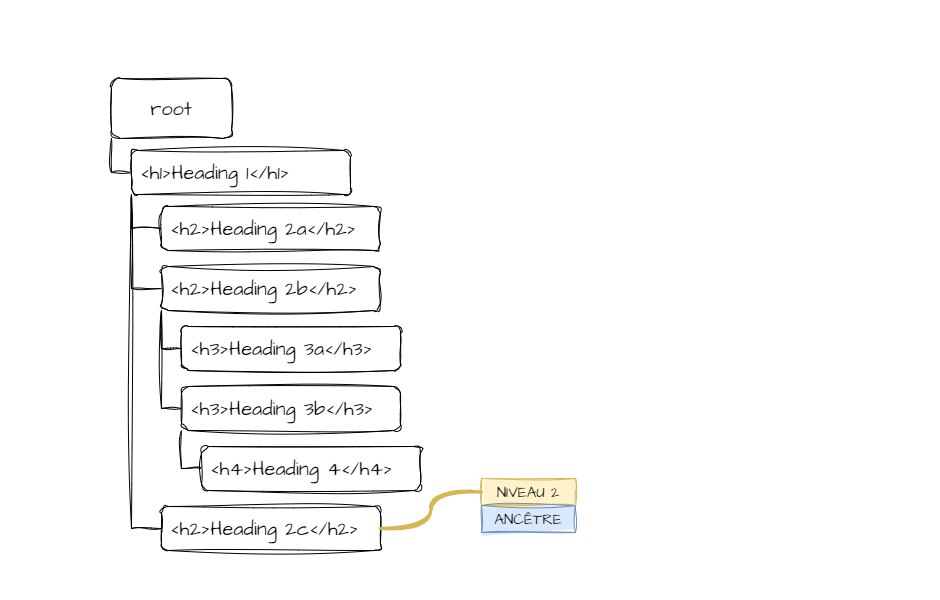
Et le nœud juste ajouté devient le nouveau nœud ancêtre.
Créer un objet
Comme déjà écrit précédemment, il me semble logique et plus simple de créer une classe pour résoudre ce problème. Ici le but est de créer une arborescence. Chaque nœud sera donc une instance de la même classe. Chaque nœud pourra avoir d'autres nœuds enfants et un nœud parent.
Le nœud racine sera un singleton. Cet objet créera les nœuds enfants.
Pour aller plus loin
Ajouter des liens dans la structure de la table des matières. Chaque lien ferait dérouler la page jusqu'au niveau de la balise d'en-tête correpondante. Les balises d'en-tête doivent alors posséder un attribut id avec une valeur. Cette valeur servira à définir le fragment de l'URL du lien.
Mais ceci n'est possible que si le document passé en paramètre est le document d'origine!
Code final
Voir le lien ou le dépôt de code


Commentaires